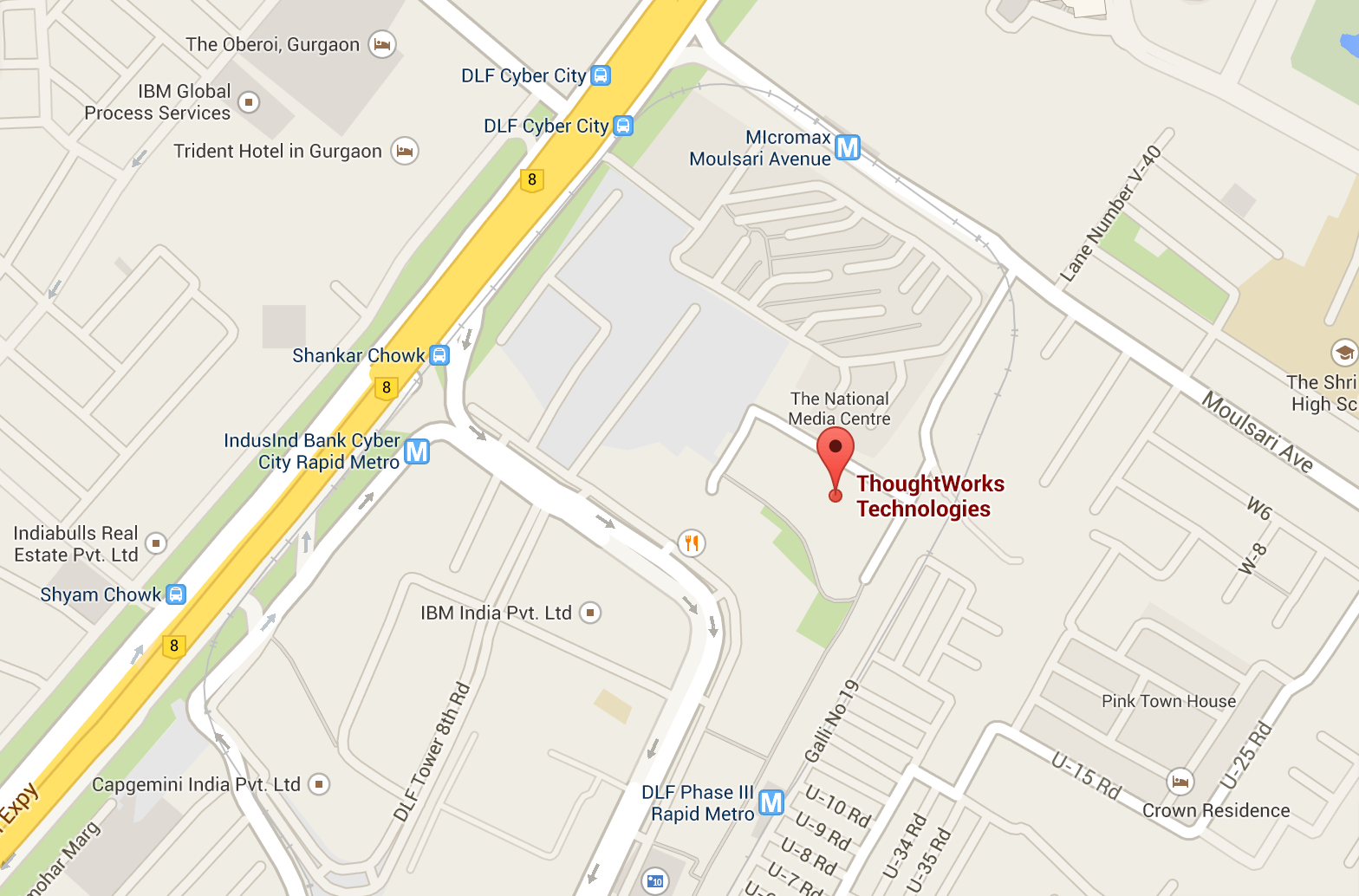
vodQA Gurgaon
'vodQA' - a platform for our peers in the software testing industry to strengthen the QA community by sharing and learning new practices and ideas. 'vodQA' offers a unique opportunity to interact with people who are equally passionate about software testing and continuously strive to better the art.
10th edition
dec 3
days
hours
minutes
seconds
Participate
registrations closed
(sorry, but check out next vodqa)